
一、rabbitmq 的使用场景有哪些?
**rabbitMQ 的使用场景,其实也就是 消息队列的使用场景。 **
- 解耦,比如说系统A会交给系统B去处理一些事情,通过将A,B中间加入消息队列,A将要处理的事情交给消息队列 ,B的输入来源于与消息队列
- 有序性。先来先处理,比如一个系统处理某件事需要很长一段时间,但是在处理这件事情时候,有其他人也发出了请求,可以把请求放在消息队里,一个一个来处理
- 消息路由:按照不同的规则,将队列中消息发送到不同的其他队列中
- 异步处理: 处理一件事情,需要 甲先做A , 然后做乙丙丁分别处理B C D ,B C D这三件事情在A之后,但是相互之间没有关联。此时甲处理A1之后,把事件发送到消息队列里边,乙丙丁接受到事件之后 分别处理B1 C1 D1。在甲处理能力比较大,BCD处理能力比较小的时候,这样做,对于A的提升能力比较大
场景1:单发送单接收==使用场景:简单的发送与接收,没有特别的处理。

 ****编辑
****编辑
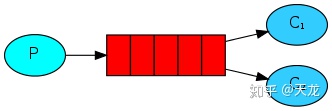
场景2:单发送多接收==使用场景:一个发送端,多个接收端,如分布式的任务派发。为了保证消息发送的可靠性,不丢失消息,使消息持久化了。同时为了防止接收端在处理消息时down掉,只有在消息处理完成后才发送ack消息。
 ****编辑
****编辑
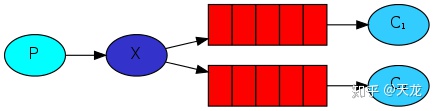
场景3:Publish/Subscribe==使用场景:发布、订阅模式,发送端发送广播消息,多个接收端接收。
 ****编辑
****编辑
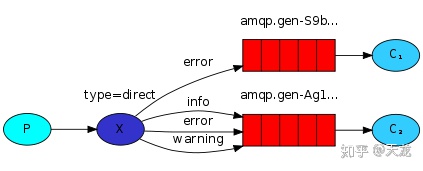
场景4:Routing (按路线发送接收)==使用场景:发送端按routing key发送消息,不同的接收端按不同的routing key接收消息。
 ****编辑
****编辑
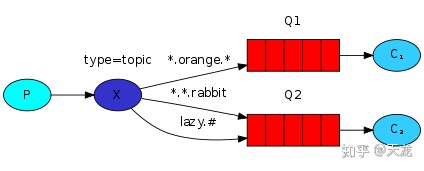
场景5:Topics (按topic发送接收)==使用场景:发送端不只按固定的routing key发送消息,而是按字符串“匹配”发送,接收端同样如此。
 ****编辑
****编辑
二、rabbitmq 有哪些重要的角色?
- 生产者:消息的创建者,负责创建和推送数据到消息服务器
- 消费者:消息的接收方,用于处理数据和确认消息
- 代理:就是RabbitMQ本身,用于扮演快递的角色,本身并不生产消息
三、rabbitmq 有哪些重要的组件?
- ConnectionFactory(连接管理器):应用程序与RabbitMQ之间建立连接的管理器
- Channel(信道):消息推送使用的通道
- Exchange(交换器):用于接受、分配消息
- Queue(队列):用于存储生产者的消息
- RoutingKey(路由键):用于把生产者的数据分配到交换器上
- BindKey(绑定键):用于把交换器的消息绑定到队列上
 ****编辑
****编辑
四、rabbitmq 中 vhost 的作用是什么?
- vhost本质上是一个mini版的RabbitMQ服务器,拥有自己的队列、绑定、交换器和权限控制;
- vhost通过在各个实例间提供逻辑上分离,允许你为不同应用程序安全保密地运行数据;
- vhost是AMQP概念的基础,必须在连接时进行指定,RabbitMQ包含了默认vhost:“/”;
- 当在RabbitMQ中创建一个用户时,用户通常会被指派给至少一个vhost,并且只能访问被指派vhost内的队列、交换器和绑定,vhost之间是绝对隔离的。
vhost可以理解为虚拟broker,即mini-RabbitMQ server,其内部均含有独立的queue、bind、exchange等,最重要的是拥有独立的权限系统,可以做到vhost范围内的用户控制。当然,从RabbitMQ全局角度,vhost可以作为不同权限隔离的手段(一个典型的例子,不同的应用可以跑在不同的vhost中)。
五、rabbitmq 的消息是怎么发送的?
首先客户端必须连接RabbitMQ服务器才能发布和消费消息,客户端 和 rabbit server 之间会创建一个tcp连接,一旦tcp打开通过了认证(认证就是你发送给rabbit服务器的用户名和密码),你的客户端 和 rabbitMQ 就创建了一条 amqp 信道(channle),信道是创建在“真实”tcp上的虚拟连接,amqp命令都是通过信道发送出去的,每个信道都会有一个唯一的id,不论是发布消息,订阅队列都是通过这个信道完成的。
六、rabbitmq 怎么保证消息的稳定性?
- 提供了事务的功能。
- 通过将 channel 设置为 confirm(确认)模式。
七、rabbitmq 怎么避免消息丢失?
- 消息持久化
- ACK确认机制
- 设置集群镜像模式
- 消息补偿机制
八、要保证消息持久化成功的条件有哪些?
- 声明队列必须设置持久化 durable 设置为 true.
- 消息推送投递模式必须设置持久化,deliveryMode 设置为 2(持久)。
- 消息已经到达持久化交换器。
- 消息已经到达持久化队列。
以上四个条件都满足才能保证消息持久化成功。
九、rabbitmq 持久化有什么缺点?
- 持久化的缺地就是降低了服务器的吞吐量,
- 因为使用的是磁盘而非内存存储,
- 从而降低了吞吐量。可尽量使用 ssd 硬盘来缓解吞吐量的问题。
十、rabbitmq 有几种广播类型?
- fanout: 所有bind到此exchange的queue都可以接收消息(纯广播,绑定到RabbitMQ的接受者都能收到消息);
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息;
- topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息;
十一、rabbitmq 怎么实现延迟消息队列?
- 通过消息过期后进入死信交换器,
- 再由交换器转发到延迟消费队列,实现延迟功能;
- 使用 RabbitMQ-delayed-message-exchange 插件实现延迟功能。
十二、rabbitmq 集群有什么用?
- 高可用:某个服务器出现问题,整个 RabbitMQ 还可以继续使用;
- 高容量:集群可以承载更多的消息量。
十三、rabbitmq 节点的类型有哪些?
- 磁盘节点:消息会存储到磁盘。
- 内存节点:消息都存储在内存中,重启服务器消息丢失,性能高于磁盘类型
十四、rabbitmq 集群搭建需要注意哪些问题?
- 各节点之间使用“--link”连接,此属性不能忽略。
- 各节点使用的 erlang cookie 值必须相同,此值相当于“秘钥”的功能,用于各节点的认证。
- 整个集群中必须包含一个磁盘节点。
十五、rabbitmq 每个节点是其他节点的完整拷贝吗?为什么?
不是 ,原因有以下两个:
- 存储空间的考虑:如果每个节点都拥有所有队列的完全拷贝,
- 这样新增节点不但没有新增存储空间,反而增加了更多的冗余数据;
性能的考虑: 如果每条消息都需要完整拷贝到每一个集群节点,那新增节点并没有提升处理消息的能力,最多是保持和单节点相同的性能甚至是更糟。
十六、rabbitmq 集群中唯一一个磁盘节点崩溃了会发生什么情况?
如果唯一磁盘的磁盘节点崩溃了,不能进行以下操作:
- 不能创建队列
- 不能创建交换器
- 不能创建绑定
- 不能添加用户
- 不能更改权限
- 不能添加和删除集群节点
唯一磁盘节点崩溃了,集群是可以保持运行的,但你不能更改任何东西
十七、rabbitmq 对集群节点停止顺序有要求吗?
RabbitMQ 对集群的停止的顺序是有要求的,应该先关闭内存节点,最后再关闭磁盘节点。如果顺序恰好相反的话,可能会造成消息的丢失。
注:以上内容仅提供参考和交流,请勿用于商业用途,如有侵权联系本人删除!
注:此博客只是为了记忆相关知识点,大部分为网络上的文章,在此向各个文章的作者表示感谢!
标题:Java 常见的面试题(RabbitMQ)
作者:wangjing
地址:https://www.codedblogs.cn/articles/2024/04/12/1712889692814.html